全连接层的推导
全连接层(full-connected layer),顾名思义,是全连接层的每一个结点都与上一层的所有结点相连,用来把前边提取到的特征综合起来。由于其全相连的特性,一般全连接层的参数也是最多的。
全连接一般会把卷积输出的二维特征图转化成一维的一个向量。
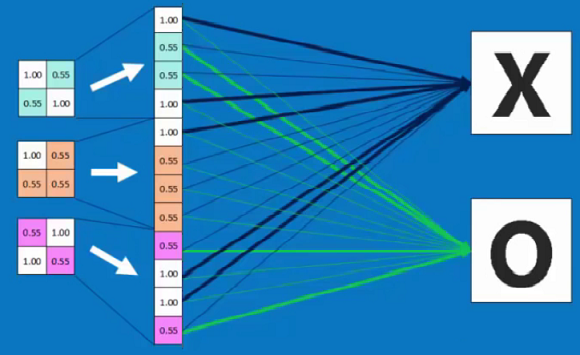
全连接层的计算其实相当于输入的特征图数据矩阵和全连接层权值矩阵进行内积。
全连接的参数是随前层大小的变化而变的,如果输入图片大小不一样,那么全连接层之前的feature map也不一样,那全连接层的参数数量就不能确定, 所以必须实现固定输入图像的大小。
全连接层的前向计算
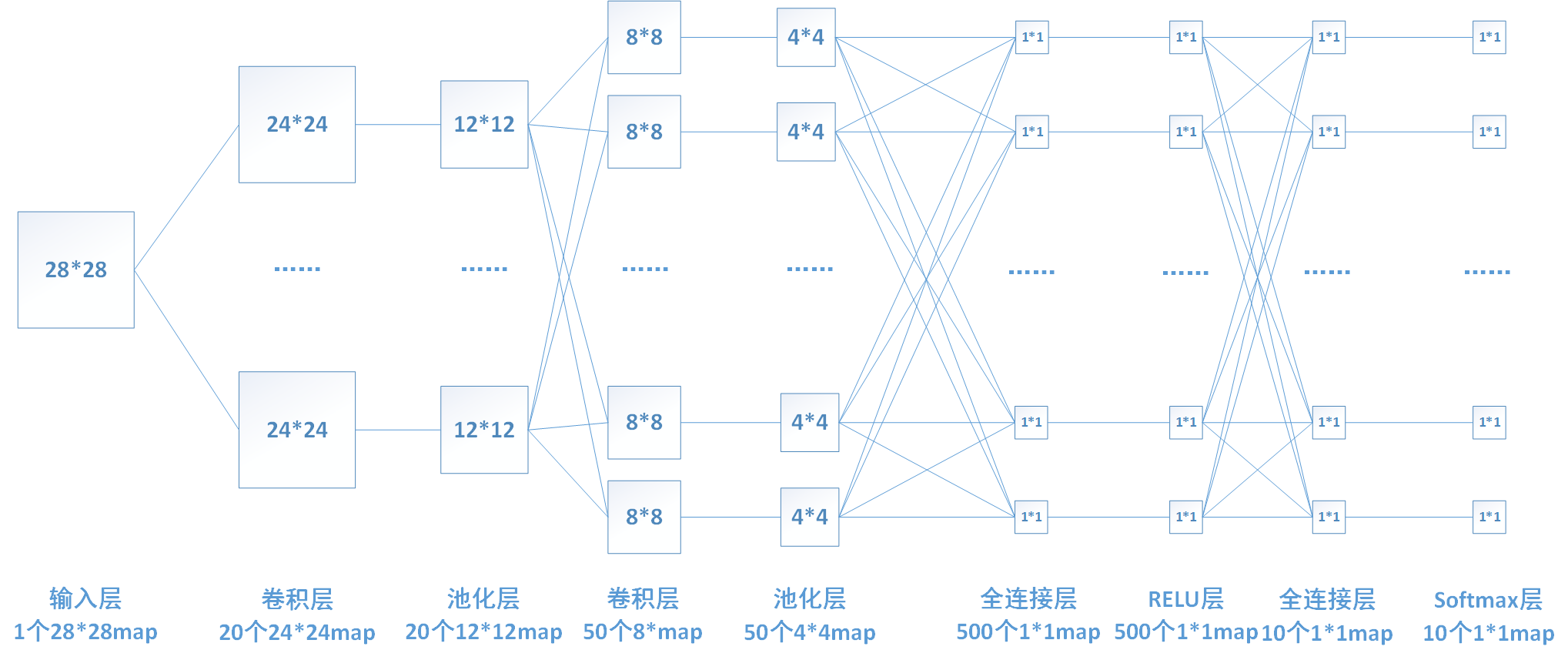
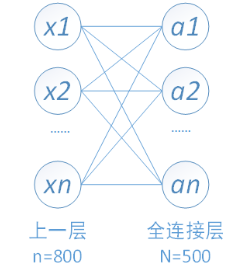
下图中连线最密集的2个地方就是全连接层,这很明显的可以看出全连接层的参数的确很多。在前向计算过程,也就是一个线性的加权求和的过程,全连接层的每一个输出都可以看成前一层的每一个结点乘以一个权重系数W,最后加上一个偏置值b得到,即 。如下图中第一个全连接层,输入有50*4*4个神经元结点,输出有500个结点,则一共需要50*4*4*500=400000个权值参数W和500个偏置参数b。
下面用一个简单的网络具体介绍一下推导过程:
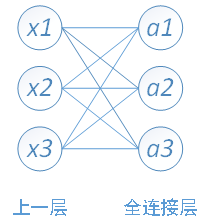
其中,x1、x2、x3为全连接层的输入,a1、a2、a3为输出,则有如下关系,向量矩阵形式为:
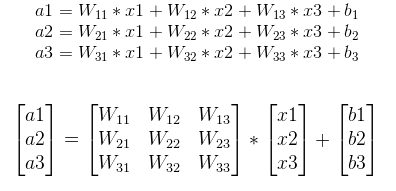
全连接层的反向传播
以我们的第一个全连接层为例,该层有50*4*4=800个输入结点和500个输出结点。
由于需要对W和b进行更新,还要向前传递梯度,所以我们需要计算如下三个偏导数。
关于梯度(Gradient)与梯度下降法(Gradient Descent)在此不再赘述,只给出其公式。
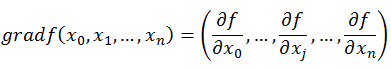
1、首先需要求得该层的输出ai对输入xj的偏导数:
若已知损失函数loss传递到该层的梯度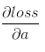 ,则我们可以通过链式法则求得loss对x的偏导数。如下:
,则我们可以通过链式法则求得loss对x的偏导数。如下:
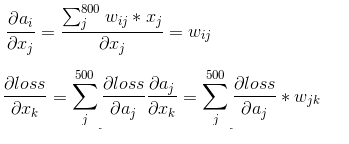
上边求导的结果也印证了我前边那句话:在反向传播过程中,若第x层的a节点通过权值W对x+1层的b节点有贡献,则在反向传播过程中,梯度通过权值W从b节点传播回a节点。
若我们的一次训练16张图片,即batch_size=16,则我们可以把计算转化为如下矩阵形式。
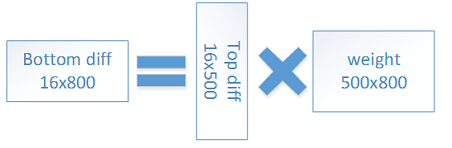
2、对权重系数Wij求偏导

3、对偏置系数bi求偏导

全连接层的作用和意义
全连接层(fully connected layers,FC)在整个卷积神经网络中起到“分类器”的作用。如果说卷积层、池化层和激活函数层等操作是将原始数据映射到隐层特征空间的话,全连接层则起到将学到的“分布式特征表示”映射到样本标记空间的作用。在实际使用中,全连接层可由卷积操作实现:
对前层是全连接的全连接层可以转化为卷积核为1x1的卷积;
而前层是卷积层的全连接层可以转化为卷积核为 h x w 的全局卷积,h和w分别为前层卷积结果的高和宽。
全连接的核心操作就是矩阵向量乘积 y = Wx
本质就是由一个特征空间线性变换到另一个特征空间。可以说,目标向量是源向量的加权和。
全连接层可以整合卷积层或者池化层中具有类别区分性的局部信息,为了提升 CNN网络性能,全连接层每个神经元的激励函数一般采用ReLU函数。
最后一层全连接层的输出值被传递给一个输出层,可以采用softmax逻辑回归(softmax regression)进行 分 类,该层也可 称为 softmax层(softmax layer)。对于一个具体的分类任务,选择一个合适的损失函数是十分重要的。
全连接层一般置于卷积神经网络的结尾,因为其参数量和计算量对输入输出数据都比较敏感,若卷积神经网络结构前期采用全连接层容易造成参数量过大,数据计算冗余,进一步使得模型容易过拟合,因此,我们采用卷积的计算过程减少了参数量,并更够提取合适的特征。但是随着深度的增加,数据信息会不断地丢失,最后采用全连接层能够保留住前面的重要信息,因此全连接与卷积的合理调整会对整个模型的性能产生至关重要的作用!
来源:
https://blog.csdn.net/lianzhng/article/details/80652744
https://blog.csdn.net/qq_39521554/article/details/81385159