谱聚类概述
来源:52ml.net 编辑:xjh 2018-04-28
聚类的直观解释是根据样本间相似度,将它们分成不同组。谱聚类的思想是将样本看作顶点,样本间的相似度看作带权的边,从而将聚类问题转为图分割问题:找到一种图分割的方法使得连接不同组的边的权重尽可能低(这意味着组间相似度要尽可能低),组内的边的权重尽可能高(这意味着组内相似度要尽可能高)。将上面的例子代入就是将每一个博客当作图上的一个顶点,然后根据相似度将这些顶点连起来,最后进行分割。分割后还连在一起的顶点就是同一类了。更具体的例子如下图所示:
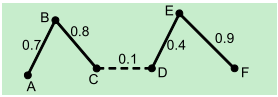
在上图中,一共有6个顶点(博客),顶点之间的连线表示两个顶点的相似度,现在要将这图分成两半(两个类),要怎样分割(去掉哪边条)?根据谱聚类的思想,应该去掉的边是用虚线表示的那条。最后,剩下的两半就分别对应两个类了。
根据这个思想,可以得到unnormalized谱聚类和normalized谱聚类,由于前者比后者简单,所以本文介绍unnormalized谱聚类的几个步骤(假设要分K个类):
(a)建立similarity graph,并用 W 表示similarity graph的带权邻接矩阵
(b)计算unnormalized graph Laplacian matrix L(L = D – W, 其中D是degree matrix)
(c)计算L的前K个最小的特征向量
(d)把这k个特征向量排列在一起组成一个N*k的矩阵,将其中每一行看作k维空间中的一个向量(或一个点),并使用 K-means 算法进行聚类
来源:
http://www.52ml.net/10397.html
https://www.cnblogs.com/pinard/p/6221564.html